
FCFS (First Come First Served) 스케쥴링
- 선입선처리 알고리즘
- 스케줄링 파라미터 : 스레드별 도착 시간
- 비선점 스케쥴링
- 스레드 우선순위 없음
- 기아 없음, 스레드 오류로 무한 루프가 발생한다면 기아 발생
- 처리율이 낮음.
- 호위 효과 (convoy effcet) 발, 긴스레드가 오래 CPU를 차지하면 늦게 들어온 스레드는 오래 대기
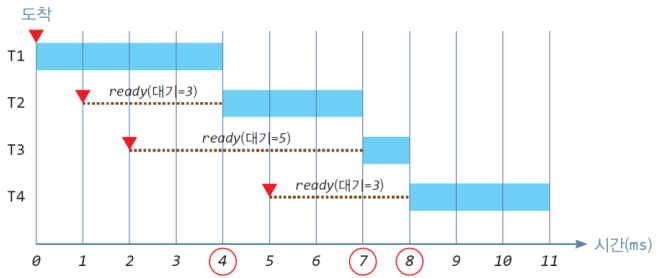
총 처리 시간 11s, 대기시간 11s, 평균 대기시간 11 / 4 = 2.75ms
SJF (Shortest Job First)
- 최단 작업 우선 스케줄링
- 스케줄링 파라미터 : 스레드 별 예상 실행 시간
- 비선점 스케줄링
- 스레드 우선순위 : 짧은 스레드 실행 시간
- 기아 발생가능, 지속적으로 짧은 스레드가 도착시 긴 스레드의 실행을 예측 불가
- 짧은 스레드가 먼저 실행되므로 평균 대기시간 최소화
- 현실적으로 실행 시간의 예측이 불가

총 처리 시간 11ms, 대기 시간 9ms, 평균 대기 시간 9ms/4 = 2.25ms
SRTF (Shortest Remaining Time First)
- 최소 잔여시간 우선 스케줄링, 타임 슬라이스 마다 남은 시간이 가장 짧은 스레드를 선택
- 스케줄링 파라미터 : 스레드 별 예상 실행 시간과 남은 실행 시간
- SJF의 선점 스케줄링
- 스레드 우선 순위 없음.
- 기아는 SJF와 마찬가지로 발생 가능
- 평균 대기시간 최소화
- SRTF도 현실적으로 사용 불가
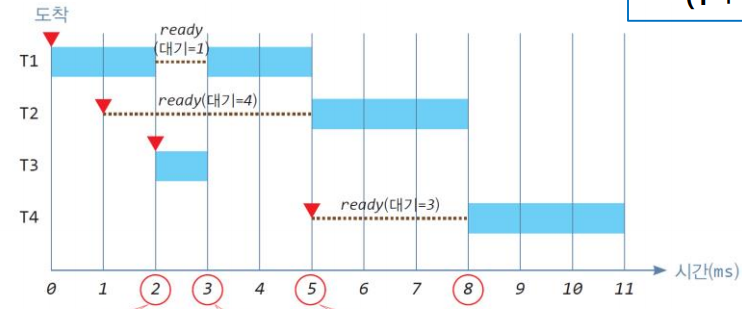
총 처리 시간 11ms, 대기 시간 8ms, 평균 대기시간 2ms
RR (Round-Robin)
- 스레드들에 공평한 실행 기회가 주어짐
- 큐에 대기중인 스레드들을 타임 슬라이스 주기로 선택
- 도착하는 순서대로 스레드들을 큐에 삽입
- 타임 슬라이스가 지나면 큐의 끝으로 이동
- 스케줄링 파라미터 : 타임 슬라이스
- 선점 스케줄링
- 우선순위 : 없음
- 기아 없음
- 구현이 쉽고 현실적으로 사용하기 쉽지만 타임 슬라이스에 따라 잦은 컨텍스트 스위칭이 발생해 오버헤드가 증가
- 타임슬라이스가 크면 FCFS와 동일하고 적으면 SJF/SRTF와 가깝다.

총 처리시간 11ms, 대기 시간 12ms, 평균 대기시간 3ms, 스케줄링 6번, 컨텍스트 스위칭 5번 발생
1. 큐에는 T1, T2, T3, T4 순서대로 삽입된다.
2. 2ms까지 T1을 처리하고 처리하다 남은 스레드는 TCB에 정보를 저장하고 다시 Queue에 삽입한다.
3. 2ms부터는 도착시간 1에 도착한 T2를 처리한다. 이 때, T2는 1ms를 대기하게 된다.
위와 같은 방법들을 반복하면 그림과 같은 결과가 나온다.
Priority 스케줄링
- 가장 높은 우선순위에 따라 스레드를 선택해서 실행 시킨다.
- 현재 스레드가 종료되거나 더 높은 순위의 스레드가 도착 시, 가장 높은 순위의 스레드를 선택
- 모든 스레드에 종료시까지 바뀌지 않는 고정 우선순위를 할당한다.
- 우선순위 큐에 삽입된다.
- 스케줄링 파라미터 : 스레드 별 고정 우선순위
- 선점/비선점 스케줄링
- 더 높은 스레드가 도착 시 선점 스케줄링
- 더 높은 스레드가 도착하지 않으면 현재 실행중인 스레드가 종료될 때 비선점 스케줄링
- 우선순위 : 있음
- 계속해서 높은 우선순위의 스레드가 도착 시, 먼저 도착한 낮은 순위의 스레드는 실행 불가
- 에이징 기법으로 해결 가능하다.
- 우선순위가 높은 스레드일수록 대기시간이나 응답시간이 짧다.
스레드 별 고정 우선순위를 가지는 실시간 시스템에서 사용된다.
MLQ (Multi-Level Queue) 스케줄링
- 스레드를 n개의 우선순위 레벨로 구분한다. 레벨이 높은 스레드를 우선적으로 처리한다.
- 고정된 n개의 큐를 사용하고 각 큐에 고정 우선순위를 할당한다.
- 스레드들의 우선순위를 n개의 레벨로 분류한다.
- 스레드 도착 시 우선순위 레벨에 맞는 큐에 삽입한다.
- 가장 높은 순위의 큐가 빌 때, 그 다음 순위의 큐에서 스케줄링한다.
- 다른 큐로 이동할 수 없다.
- 나머지 내용은 Priority Queue와 동일하다.
실 사용 예로 전체 스레드를 백그라운드와 포그라운드 스레드로 구성하거나 시스템 스레드, 대화식 스레드, 배치 스레드 등 3개의 레벨 큐로 구성한다.
MLFQ (Multi-Level Feedback Queue) 스케줄링
- 기아를 없애기 위해 여러 레벨의 큐 사이에 스레드 이동이 가능하도록 설계되었다.
- 짧은 스레드와 I/O가 많은 스레드, 대화식 스레드를 우선 처리해서 스레드 평균 대기시간을 줄인다.
- MLQ와 같이 N개의 고정 레벨 큐를 가지고 큐마다 서로 다른 스케줄링 알고리즘을 적용한다.
- 큐마다 스레드가 머무를 수 있는 큐 타임슬라이스가 있다.
- 낮은 레벨의 큐일수록 타임슬라이스가 더 길다.
- I/O 집중 스레드는 높은 순위의 큐에 있다.
- 스레드는 도착 시 최상위 레벨 큐에 삽입
- 가장 높은 레벨의 큐에서 스레드를 선택
- 가장 높은 레벨의 큐가 비어있으면 그 아래 레벨의 큐에서 스레드를 선택
- 스레드의 CPU-burst가 큐 타임 슬라이스를 초과하면 아래 큐로 이동
- 스레드가 자발적으로 Yield 한 경우, 큐 끝에 삽입
- 스레드가 I/O 발생 시, I/O가 종료되면 동일한 레벨 큐의 끝으로 이동
- 큐에 있는 시간이 오래되면 기아를 막기 위해 큐 레벨업
- 최하위 레벨 큐는 FCFS나 TimeSlice 가 긴 RR로 스케줄한다.
- 최하위 레벨 큐에 속한 스레드들은 다른 큐로 이동할 수 없다.
- 스케줄링 파라미터 : 각 큐의 시간 할당량
- 선점 스케줄링
- 스레드 우선순위는 없음, 큐에 따른 우선순위가 있음.
- 에이징 기법을 적용함으로 기아가 발생하지 않는다.
- I/O 집중 스레드나 Cput burst가 짧은 큐를 높은 레벨에서 빨리 실행함으로 CPU 활용률이 높아진다.


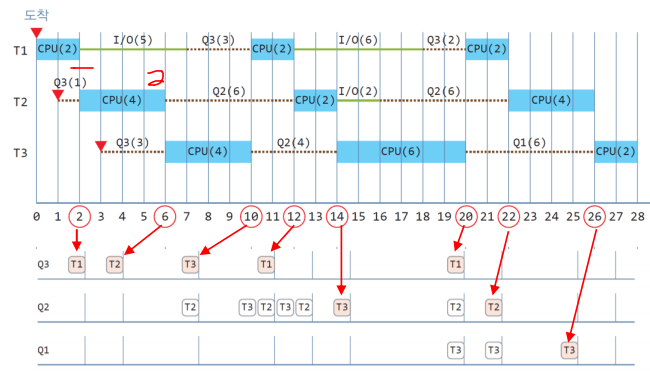
| Time | Queue3 | Queue2 | Queue1 | Wait Time | Schedule info |
| 0 | T1 | q3.pop() - T1 처리 | |||
| 1 | T2 | T1 처리 T2 대기 |
|||
| 2 | T2 | T2 - 1ms | q3.pop() - T2처리 T1 - I/O 작업 |
||
| 3 | T3 | T2처리 T3 대기 |
|||
| 4 | T3 | T3 - 1ms | T2처리 T3 대기 |
||
| 5 | T3 | T3 - 2ms | T2처리 T3 대기 |
||
| 6 | T3 | T3 - 3ms | T2 Time slice 초과, Q3.pop() - T3처리, Q2.push(T2) - T2 대기 |
||
| 7 | T2 | T2 - 1ms | T3 처리 T1 I/O 작업 종료 - 같은 레벨 Q3.push(T1) T1, T2 대기 |
||
| 8 | T1 | T2 | T2 - 2ms, T1 - 1ms | T3 처리 T1, T2 대기 |
|
| 9 | T1 | T2 | T2 - 3ms, T1 - 2ms | T3 처리 T1, T2 대기 |
|
| 10 | T1 | T2 | T2 - 4ms, T1 - 3ms | T3 Time Slice 초과, 하위레벨 Q2.push(T3) 최상위 Q3.pop() - T1처리 T2 대기, T3 대기 |
|
| 11 | T2, T3 | T2 - 5ms, T3 - 1ms | T1 처리 T2, T3 대기 |
||
| 12 | T2, T3 | T2 - 6ms, T3 - 2ms | T1 처리 완료 및 I/O작업 최상위 Q2.pop() - T2 처리 T3 대기 |
||
| 13 | T3 | T3 - 3ms | T2 처리 T3 대기 |
||
| 14 | T3 | T3 - 4ms | T2 처리 완료 및 I/O 작업 최상위 Q2.pop() - T3 처리 |
||
| 15 | T3 처리 | ||||
| 16 | T2 | T3 처리 T2 I/O 작업 종료 - 같은 레벨 Q2.push(T2) T2 대기 |
|||
| 17 | T2 | T2 - 1ms | T3 처리 T2 대기 |
||
| 18 | T2 | T2 - 2ms | T3 처리 T1 I/O 작업 종료 - 같은 레벨 Q3.push(T1) T1, T2 대기 |
||
| 19 | T1 | T2 | T2 - 3ms, T1 - 1ms | T3 처리 T1, T2 대기 |
|
| 20 | T1 | T2 | T2 - 4ms, T1 - 2ms | T3 Time Slice 초과, 하위레벨 Q1.push(T3) 최상위 Q3.pop() - T1 처리 T2 대기 |
|
| 21 | T2 | T3 | T2 - 5ms, T3 - 1ms | T1 처리 T2, T3 대기 |
|
| 22 | T2 | T3 | T2 - 6ms, T3 - 2ms | T1 처리 완료 최상위 Q2.pop() - T2 처리 T3 대기 |
|
| 23 | T3 | T3 - 3ms | T2 처리 T3 대기 |
||
| 24 | T3 | T3 - 4ms | T2 처리 T3 대기 |
||
| 25 | T3 | T3 - 5ms | T2 처리 T3 대기 |
||
| 26 | T3 | T3 - 6ms | T2 처리 완료 최상위 Q1.pop() - T3 처리 |
||
| 27 | T3 처리 | ||||
| 28 | T3 처리 완료 스케줄링 종료 |
3개의 스레드 처리 시간 28ms
스레드별 대기 시간 5ms, 13ms, 13ms
평균 대기 시간 31ms/3 = 10.3ms
'CS > 운영체제' 카테고리의 다른 글
| 17. 상호 배제 (Mutual Exclusion) (0) | 2024.06.15 |
|---|---|
| 16. 스레드 동기화 (Thread Synchronization) (0) | 2024.06.15 |
| 14. CPU Scheduling (0) | 2024.04.22 |
| 13. 멀티스레드 구현 (0) | 2024.04.22 |
| 12. 커널 레벨 스레드와 사용자 레벨 스레드 (1) | 2024.04.22 |

